Our new model, Coda, is now live in the dashboard and API!
Introducing Arcana: AI Voices with Vibes 🔮

By
The Rime team

At Rime, we’re driven by the belief that foundational AI models should reflect the full richness and diversity of how people really speak. All the messy imperfections, subtly changing prosody, and hi-fi mouth sounds. The hidden magic behind human speech.
Today, we are sooo excited to release Arcana, the most realistic spoken language model you’ve ever heard.
A live chat demo powered by Arcana’s eight flagship voices is on the Rime homepage now. Try chatting with Arcana! Which voice will you get?
(Psst. Here’s a forkable open source repo to try the demo locally too.)
We trained Arcana on our massive, proprietary dataset of richly-labeled conversational speech with everyday people. Due to our data and novel architectural approach, we’re also able to include some truly groundbreaking new features in beta, such as generating infinite voices based on just a description or fictional name or even getting the model to laugh. Read on for more.
While Arcana is built for generating ultra-realistic speech for creative and business use cases, our Mist v2 model remains the fastest and most customizable text-to-speech (TTS) model for high-volume business applications. There’s a 1:1 speaker overlap between the two models, which ensures continuity in your applications.
We also designed this new model with developers in mind. It’s production-ready and API-accessible from day one. No waitlists, no hidden gates, no eval-only constraints. You’ll find building with Arcana refreshingly straightforward.
So whether you’re deploying an enterprise application, shipping a fun chatbot, prototyping experimental voice UIs, or just wiring together a few APIs, the stars are aligned. Go ahead, just start building!
<div data-src="https://pub-a388dd8413ab4c478adabdb2f61495b7.r2.dev/launching-arcana/rich_prosodic_understanding.wav" data-caption="Readings with rich prosodic understanding"></div>
Technical Report
Arcana is the first in a class of new spoken language models created by Rime. It infers emotion from context. It laughs, sighs, hums, audibly breathes, and makes subtle mouth noises. It says um and other disfluencies naturally. It has emergent behaviors we are still discovering. In short, it acts human.
These are truly novel, frontier capabilities. And we expect to go beyond, building on this research with even more realistic versions of Arcana, new speech-to-speech models, native understanding of voice, multimodal models, and more.
Our massive dataset combined with our deep expertise in both machine learning and linguistics make Rime uniquely able to deliver on these capabilities.
Rime is also deeply committed to giving back to the community. Earlier in April, we open sourced Rimecaster, our realistic speaker representation model, which has already been downloaded thousands of times and will dramatically improve the development of new voice AI models.
Let’s dive in.
Model Architecture
Arcana is a multimodal, autoregressive text-to-speech (TTS) model that generates discrete audio tokens from text inputs. These tokens are decoded into high-fidelity speech using a novel codec-based approach, enabling faster-than-real-time synthesis.
Backbone: A large language model (LLM) trained on extensive text and audio data.
Audio Codec: Utilizes a high-resolution codec to capture nuanced acoustic details.
Tokenization: Employs a discrete tokenization process to represent audio features effectively.
Similar to work by Canopy on Orpheus, we use a pre-trained LLM to auto-regressively decode flattened codec representations, ordered coarsest to finest.
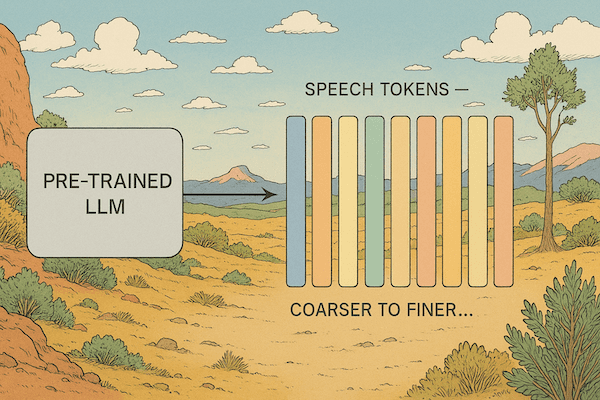
Model Training
Arcana's training involved a three-stage process:
Pre-training: We leveraged open-source LLM backbones and did additional pre-training on a large corpus of text-audio pairs to learn general linguistic and acoustic patterns.
Supervised fine-tuning (SFT): We completed the initial fine-tuning with our massive, proprietary dataset, which gives the model its unmatched realism and emergent capabilities.
Our data is based on sociolinguistically-sophisticated conversation techniques to record and encode the subtleties of each accent and idiolect (the speech habits for a particular person), such as allophonic variation, phonemic splits, and chain shifts. This includes both subconscious and rhetorical use of filler words (such as uh and um), pauses, and prosodic stress patterns. We also capture multi-lingual code-switching. The result is a highly-curated and richly-labeled dataset of expressive conversational speech, coupled with detailed speaker demographics.
Speaker-specific fine-tuning: We then took our most exemplary speakers and optimized the model for conversations and reliability, resulting in eight flagship voices for Arcana plus consistency with our Mist v2 model.
Implications for Fictional Speaker Genesis
Due to Arcana’s architecture, it can correspondingly take advantage of the linguistic and semantic information that is encoded within pretrained text and acoustic models.
By leveraging this rich semantic context and fine-tuning on speaker data including explicit text labels with demographic information, Arcana can generate novel voices on the fly, just by providing a description or fictional name.
For example you can ask Arcana to generate speech following these patterns speaker: “a young woman working in tech” or speaker: “chen_william”.
<div data-src="https://pub-a388dd8413ab4c478adabdb2f61495b7.r2.dev/launching-arcana/young-woman-in-tech.wav" data-caption="A young woman working in tech: "Oh, hey there. How are you doing?"></div>
<div data-src="https://pub-a388dd8413ab4c478adabdb2f61495b7.r2.dev/launching-arcana/william-chen.wav" data-caption="William Chen (fictional): "Oh hey there, how are you doing?"></div>
So Arcana is infinitely multi-speaker out of the box. See the use cases below for more.
Laughter and Emergent Model Behavior
Arcana can insert laughter (and other paralinguistic nuances, like sighs) into speech just by including a token like <laugh> in the inputted text, for example: text: "Oh, hey <laugh>".
This is an emergent behavior and still in beta. The model generally interprets <laugh> correctly in the text input, with varied and realistic output ranging from a small chuckle to a big guffaw. Although not explicitly trained for this, the model also often interprets <chuckle>, <sigh> and even <hum> correctly. We are exploring other input tokens and evaluating the model's behavior.
<div data-src="https://pub-a388dd8413ab4c478adabdb2f61495b7.r2.dev/launching-arcana/oh-hey-laugh.wav" data-caption="Oh hey <laugh>"></div>
See the use cases below for more.
In most speech demos, there is a separation between an LLM that generates text and a TTS model that turns the text to speech. This allows a lot of control over the text that's generated, which is critically important for real world use cases. But a big problem with the LLM and TTS handoff is having stringent boundary conditions, for example, if an LLM generates words, phrases, or patterns that a TTS model hasn't been trained on, it typically won't behave desirably.
High profile voice-to-voice demos avoid this problem by avoiding the handoff, but then they are much harder to tune for specific applications because there's so much implicit heavy lifting happening under the hood. You can't easily solve domain-specific last mile problems, like sticking to a strict script or pronouncing brand names or esoteric vocabulary, which means it's hard to switch a voice-to-voice model from one use case to another.
What's exciting about Arcana is that the boundary conditions are more fluid and controllable. For example if an LLM can insert tokens like <laugh> in its output and a TTS model can correctly render them, this is a big deal because even if the LLM hallucinates a new token type, such as <cough> or <burp>, the TTS could potentially reason about it.
We're excited to do more research along these lines.
A Deeper Dive on Rime’s Approach to Data
At Rime, we prioritize the authenticity and diversity of our training data. Unlike many models that rely on read-speech data scraped online, which often lacks the nuances of everyday conversation, we built Arcana using full-duplex, multi-lingual speech data recorded from real conversations with everyday people in our San Francisco studio and other locations across the U.S.
To ensure the highest quality, we employ a team of multi-lingual PhD annotators to produce "gold-level" transcriptions, achieving 98-100% accuracy. This meticulous approach ensures that Arcana captures the subtle nuances of human speech, including accents, emotions, and conversational dynamics. We also capture comprehensive demographic and sociolinguistic details.
This includes encoding and enabling code-switching between languages in a single utterance, controlling laughter, yawning, and more that occur simultaneously with speech, and meta-linguistic alternate voicings such as whispering, sarcasm, and mockery, which no other TTS can offer. Well, they were until now…
Just to illustrate why expertise in computational linguistics really matters when building top performing spoken language models, here are two challenges we faced when training our models and how we creatively solved them:
Improve realism with more characteristics of speech:
Encode the non-discrete, gradient effects of speech: Traditional text encodes very little beyond the basic words used and a handful of ambiguous punctuation marks. In order to capture and manipulate the actual multivarious range of speech, we developed an augmented metatext encoding schema to give greater intuitive control to users, allowing them more command over the model.
This is why Arcana sounds better than models trained only on text, which struggle to reproduce realistic artifacts of speech or to infer emotion without receiving additional context.
Allow users to generate infinite new voices:
Make the massive latent voice space accessible: We’ve collected and are constantly augmenting our massive, proprietary conversational speech dataset. But making this rich multidimensional space easily traversable and empowering demands that we collect and annotate each voice with detailed metadata, encoding age, gender, dialect, affect, language(s), etc.
In fixing this, we've been able to allow users to stipulate general demographic characteristics of the voices they desire.
Performance Metrics
Honestly, we're pretty skeptical of those first-party benchmarks that a lot of new models include in their launch announcements (and many others feel the same way). So rather than delay our launch to cobble together some charts and graphs that hardly anyone will view or trust, we've kept our heads down, working furiously, so we could ship Arcana as fast as possible.
That said, here are a couple stats we are excited to share:
Time to first audio token is 200ms.
Public cloud latency is ~300ms
Note: network latency varies with distance from our public internet API endpoints and other factors. Contact us if you'd like to discuss options to lower latency for high-volume applications.
(EDITED May 9, 2025. Note: time to first audio at launch was 250ms and public cloud latency was ~400ms.)
We expect to bring latency down even further in the coming weeks, getting closer to our best-in-class Mist v2 latency metrics (~80ms model latency and ~200ms over public cloud).
And we're planning to work with third parties to ensure you get reliable metrics on how Rime stacks up. But don't wait on that. We hustled hard so you could experience the new frontier in voice AI right away.
How to Get Started
Getting started with Arcana is as simple as signing up for a Rime account and using our dashboard to start synthesizing audio or generating an API key.
Here’s a simple curl request to generate an mp3 audio stream from the command line (or to paste into your favorite vibe coding editor).
<div data-src="https://pub-a388dd8413ab4c478adabdb2f61495b7.r2.dev/launching-arcana/laugh_hey_whats_up.wav" data-caption="<laugh> Hey, what's up? So what're you excited to build?"></div>
If you'd like a more complete starting point, we've open sourced a github repo with detailed instructions. It's similar to the live chat demo on the Rime homepage, is built with LiveKit agents, and includes speech recognition (ASR), text understanding (LLM), and speech synthesis (TTS). We expect to release additional starter kits with other tech stacks soon.
Check our docs for more detailed info.
Use Cases and Examples
Flagship Speakers
We are launching Arcana with eight flagship speakers exemplifying the diverse capabilities of the model.
luna (female, chill but excitable, gen-z optimist)
celeste (female, warm, laid-back, fun-loving)
orion (male, older, african american, happy)
ursa (male, 20 years old, encyclopedic knowledge of 2000s emo)
astra (female, young, wide-eyed)
esther (female, older, chinese american, loving)
estelle (female, middle-aged, african-american, sounds so sweet)
andromeda (female, young, breathy, yoga vibes)
Hear them all in the Rime dashboard!
<div data-src="https://pub-a388dd8413ab4c478adabdb2f61495b7.r2.dev/launching-arcana/hi-esther.wav" data-caption="Hi, my mame is Esther! Nice to meet you!"></div>
<div data-src="https://pub-a388dd8413ab4c478adabdb2f61495b7.r2.dev/launching-arcana/i-will-follow-you.wav" data-caption="So um like, "I Will Follow You Into the Dark" was totally Death Cab at their most, I dunno, tender? Like, this stripped-down, acoustic heart-to-heart about love and mortality. It’s kinda devastating, but in that soft way that just sits quietly in your chest."></div>
<div data-src="https://pub-a388dd8413ab4c478adabdb2f61495b7.r2.dev/launching-arcana/hi-im-andromeda.wav" data-caption="Hey, I’m Andromeda—uh, I’m really into yoga, like breathwork and all that good stuff... and I kinda love the moon a little too much."></div>
Infinite Speaker Generation (beta)
Instantly create unique, consistent voices by providing just a description or a fictional name. Great for support agents, games, virtual assistants, or personalized educational tools.
<div data-src="https://pub-a388dd8413ab4c478adabdb2f61495b7.r2.dev/launching-arcana/fear-little-buzz.wav" data-caption="Fear’s just that little buzz before the wave, man. Once you’re in, it’s all stoke and flow."></div>
<div data-src="https://pub-a388dd8413ab4c478adabdb2f61495b7.r2.dev/launching-arcana/hi-good-to-see-you.wav" data-caption="Hi, good to see you. What are your plans this weekend?"></div>
Paralinguistic Nuances & Natural Laughter (beta)
Capture genuine human speech with subtle cues like sighs, and fillers. Arcana also realistically generates laughter, adding warmth and authenticity to interactions. Ideal for immersive storytelling, chatbots, and customer interactions.
<div data-src="https://pub-a388dd8413ab4c478adabdb2f61495b7.r2.dev/launching-arcana/laughter" data-caption="laughter"></div>
<div data-src="https://pub-a388dd8413ab4c478adabdb2f61495b7.r2.dev/launching-arcana/sigh-idk.wav" data-caption="<sigh> I just don't know what to do."></div>
<div data-src="https://pub-a388dd8413ab4c478adabdb2f61495b7.r2.dev/launching-arcana/hey-you-suck.wav" data-caption="hey, you suck! <long evil laugh>"></div>
It won't always work, but if you're feeling creative, you can also try totally new tokens inside brackets <>.
Code-Switching & Multilingual Fluency (beta)
Arcana seamlessly blends languages, handling natural multilingual conversations effortlessly. Perfect for apps and agents targeting global, diverse audiences.
<div data-src="https://pub-a388dd8413ab4c478adabdb2f61495b7.r2.dev/launching-arcana/me-llamo-sophia.wav" data-caption="Oh hey, me llamo Sofía. I’m just chillin, ya tú sabes. What you doin’ later? Wanna hang out conmigo?"></div>
Highly Controllable
Arcana saw richly annotated text-audio pairs during post-training, which results in a high degree of controllability. Speech generated is responsive to nuanced controls in the text, including markdown-like semantics:
<div data-src="https://pub-a388dd8413ab4c478adabdb2f61495b7.r2.dev/launching-arcana/markdown.wav" data-caption="markdown"></div>
Extreme Expressivity
Having been trained on an enormous amount of text and audio, Arcana has a deep contextual understanding of the mapping between text and acoustic information.
<div data-src="https://pub-a388dd8413ab4c478adabdb2f61495b7.r2.dev/launching-arcana/extreme-expressivity.wav" data-caption="extreme expressivity"></div>
Core Use Cases
While Arcana offers ultra-realistic voices ideal for creative and conversational applications, Mist v2 is optimized for high-volume, business-critical use cases requiring speed, accuracy, and customizability.
Our most cutting-edge customers use both models in the same conversations, with Arcana handling more open-ended responses and greetings and Mist v2 pronouncing product names, spelling emails, reading out customer IDs, etc. This is the most effective way to convert prospects, retain customers, and drive sales.
Both Arcana and Mist v2 support Rime’s core use cases like customer support, fast-food ordering, outbound calling, audiobook narration, and streamlining voice AI operations across restaurants, financial services, healthcare, transportation, hospitality, and revenue-focused outbound calling. Read more about our use cases.
Looking Ahead
Arcana is just another step in our ambitious roadmap at Rime. We're excited to push the frontier of what's possible with voice AI, continually improving both realism and business impact. We aim to delight.
Expect more exciting model updates, expanded developer tooling, and additional open-source contributions all designed to empower builders around the world.
We can't wait to hear what you build with Arcana. Let’s keep innovating together!