Our new model, Coda, is now live in the dashboard and API!
Introducing Coda: The last TTS you'll ever need

By
The Rime team

Today we are introducing Coda, the last text-to-speech model you’ll ever need. We don’t say that lightly.
We believe in the bitter lesson, and in speech that means that the future of all voice applications will be increasingly bound up in ‘end-to-end’ modeling paradigms. But we also believe in building with purpose to solve problems that teams of developers building voice agents face today.
The Pareto principle applies in voice AI more than ever before: the last mile is a hundred miles long. Coda is what happens when a team refuses to be distracted from that fact.
The headline numbers (latency, concurrency, quality) speak for themselves: Coda blows our competitors out of the water on each of these metrics. Why? Because we're the only team that's only focused on this.
Every model release in this space comes wrapped in the same marketing claims: fastest, most realistic, most natural. But in practice, there's always been a tradeoff. We reject that tradeoff.
There are certain things we should stop talking about because they're table stakes, like low latency and the “humanlike” quality of a voice.
So what’s next? There are two categories of voice work that matter today: being the voice for content, and being the voice of conversation.
Who is Coda for?
Coda is built for high-stakes conversations, because at scale, every detail matters.
There’s a high likelihood that if you’ve called a business in the last two years - you’ve already heard Rime. We’re talking about customer support, yes, but we’re talking about much more than that. We measure our success not by how many brand experiences we power, but by our ability to increase the empathy, the relatability, the meaning of these conversations.
We're solving the problem of voice in the loop with a real human, in real time, where the stakes are real, and where the cost of a hang-up shouldn’t be measured by resolution rate or containment but by someone’s willingness to engage.
How we got here
When we started Rime, we saw two persistent problems in the market that nobody was solving in tandem.
The first is a stubborn tradeoff between quality and reliability. You could have a model that sounded decent in a demo but it fell apart at prod concurrency, or it mispronounced the most important word in a conversation.
The second is harder to name but easier to recognize: studio-quality output that was conversationally dead. Once you hear it, you can't unhear it. The human brain is exceptionally good at pattern matching, and you know when you're hearing slop. You know when a voice has been optimized for a podcast clip rather than a back-and-forth exchange. You know when the model has never heard a real conversation in its life.
Rime's position has always been simple: we are craftspeople shaping the future of voice AI.
What is Rime’s Craft?
Craft starts with the data. We built a proprietary, full-duplex conversational speech dataset before we trained a single model. We started in a recording studio in San Francisco.

Craft continues into the architectural decisions. As opposed to Arcana v3, Coda leverages two, jointly-trained autoregressive decoders, one for semantic understanding and the other for acoustic understanding.
This approach preserves the acoustic reconstruction capabilities that carry rich speaker information: pitch contour, breath, hesitation, all the things that make a voice human, and additionally lets us model the very particular duration characteristics of real conversation with much higher fidelity than a single-decoder design. Conversation has a rhythm that monologue doesn't, and Coda is built to capture it.
Craft also lives in the infrastructure. We wrote our own dual-decoder inference stack from the ground up, and it materially outperforms off-the-shelf implementations. Coda runs on TIGERSTRIPE, the serving and orchestration layer we've been building in parallel with the model itself, and can be delivered and run on-prem like all other Rime models.
What we’ve learned
Compared to Arcana, our previous flagship, Coda outperforms across the board, with the biggest gains in multilingual settings.
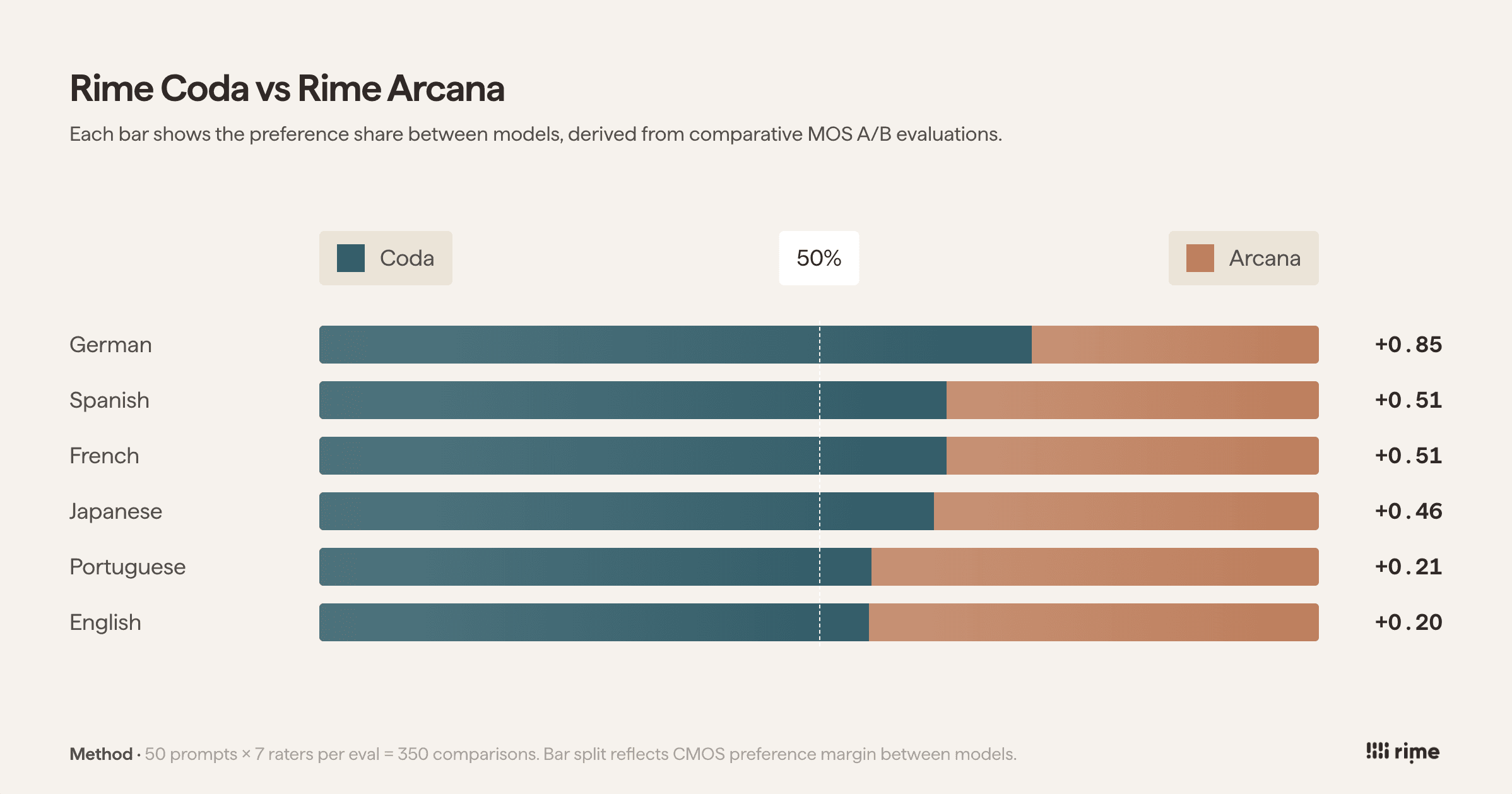
Compared to the competition, it's not close.
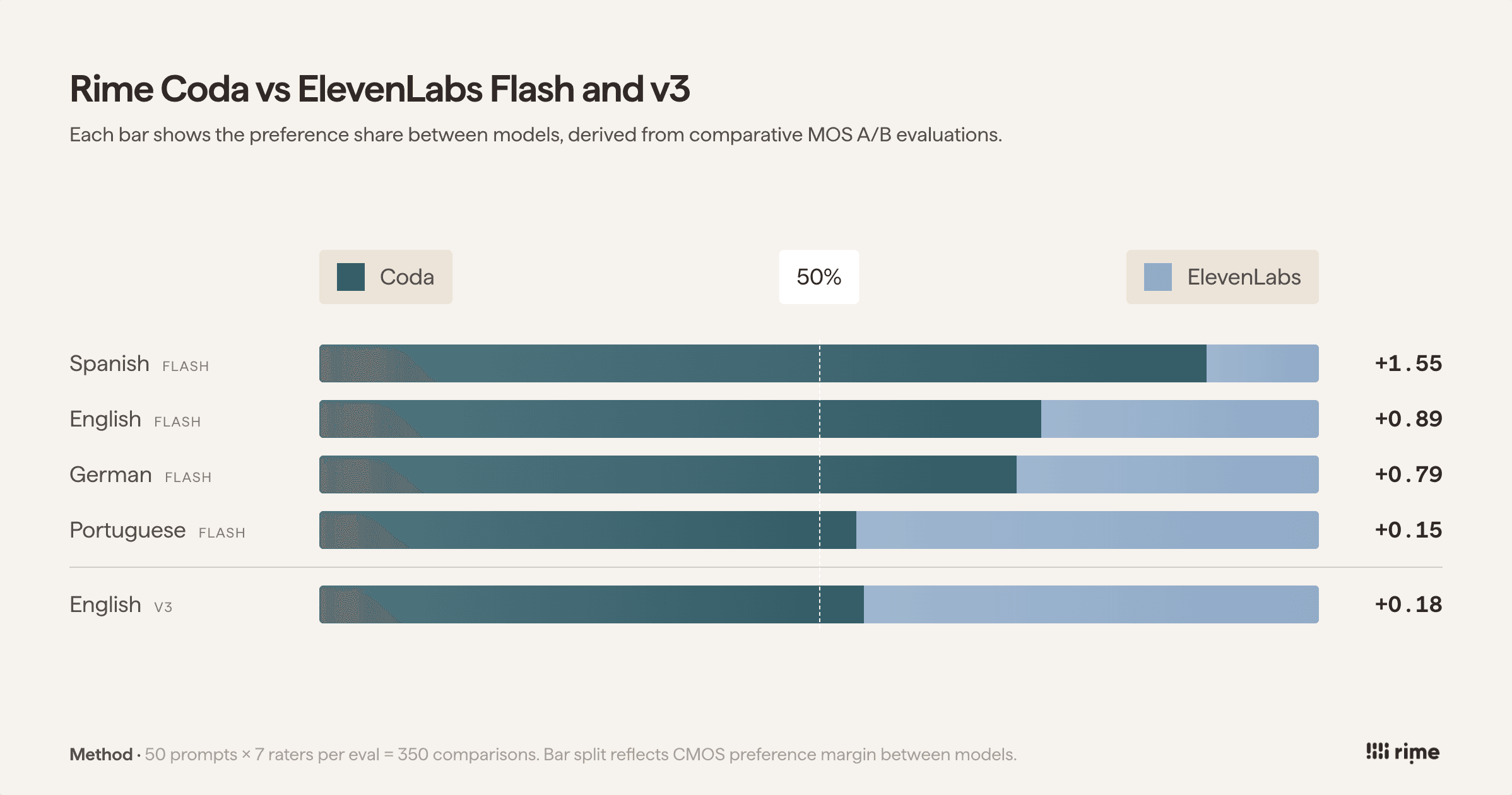
You can view the ElevenLabs comparison here on Podonos.
Start using Coda today
Coda is built on top of years of hard work: the largest dataset of studio quality, everyday speech. Listen and hear for yourself.
Coda is live in public beta. Sign up to start building, or get in touch with our team if you're working on something where the details matter and you want to talk it through with us.