A person's accent is one of their most personal and unique characteristics. At Rime, we think no one should have to change theirs. But synthetic people on the other hand...
We've split the atom! (of timbre and accent)
Here in the Rime lab, we've developed the ability to swap out a speaker's original accent and replace it with a different one.
This is a game-changer. Let's look into the details.
What Goes Into How You Speak
The way that an individual sounds when they speak is determined by two major factors:
- The shape of their vocal tract, which contributes to their personally identificable timbre
- The particular phonological rules and sound inventory of their idiolect, which contributes to their accent.
However, teasing these two apart in generative speech synthesis is pretty tricky. When a person speaks, the output is a complex sound wave, which comprises the phonetic particularities of both their timbre and accent. Seen below is the spectrogram of the baseline audio above. The way the synthetic speaker pronounces his words depends on both components, and it's not (currently) possible to isolate them.
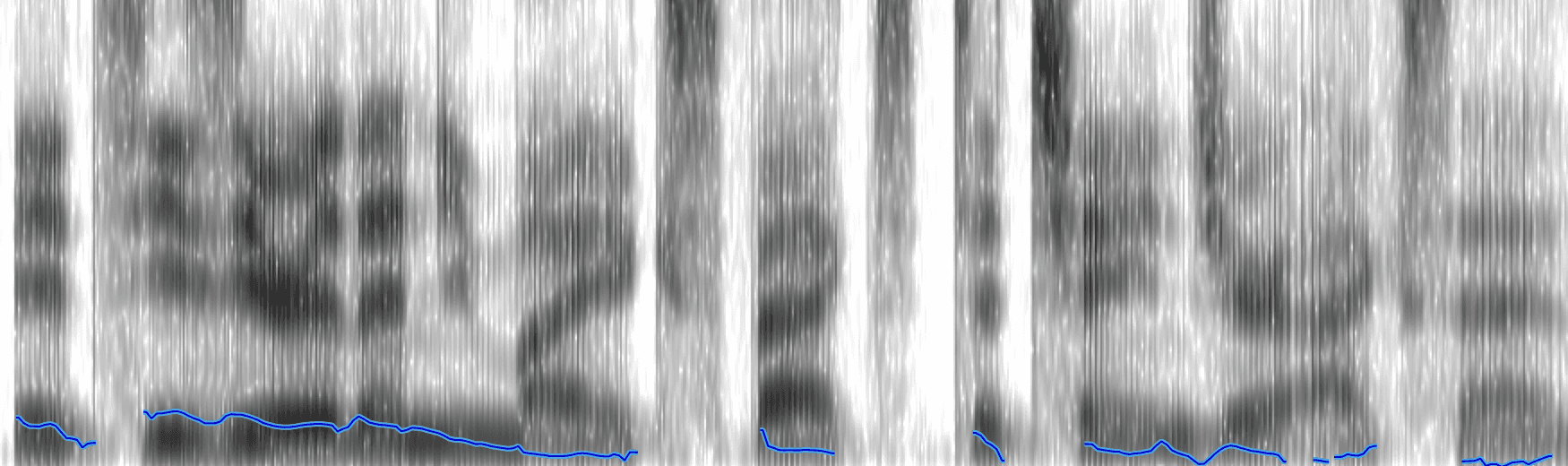
But note the blue line in the image. This represents the pitch of the speech and this is one fair proxy for his unique timbre.
Another good proxy for timbre is the fourth formant, the topmost thick black band in the above image. We can measure that formant for each transferred accent and compare them to each other.
With that said, simply listening to the audio can be a best approximation for the retention of individual timbre across accents.
The average pitch of the baseline audio above is 98Hz and that of the Texan accented version of the same speaker is a very similar 100Hz. The average fourth formant for the baseline is 3731Hz and the Texan version is 3745Hz, again extremely close. Let's look at some more below.
A Range of Accents for one Speaker
Below, we've taken that same speaker (whose baseline is a fairly standard Californian accent) and transferred other accents onto his voice. Of course, this process can go in any direction: from Texan to Australian, from Boston to AAVE. For each, I've included the average pitch (p) and average fourth formant (F4) measurements, both measured in Hz.
Another speaker
Of course, the same accent transfer can be done with female speakers as well. The main difference between male and female speakers again lies in pitch and the fourth formant.
Wrapping Up
There's more work to be done in this realm, but we're really excited about the possibilities here, whether it's for programmatic advertising, demographic-specific call automation, or anything else you might think up! Keep following the Rime blog for more updates!
More from the lab
.png)
Guide: Design and run an A/B test of your AI voices on real calls using Claude and Cursor
Anything can sound great in a demo, but what do your callers actually prefer? Test multiple voices and vendors in your own experiment with this guide. Get benchmarks to measure against and prompts that you can execute in Claude and Cursor today.

