When we launched Coda last week, the training itself wasn't the only hard problem. We also had to pick the top few voices from 180+ candidates, group them into simple categories, and make sure the labels matched real world use cases.
The Coda model could have been everything we promised and still failed if the voice catalog wasn't right for our customers.
So we partnered with Podonos, the audio evaluation platform, and ran more than eight thousand pairwise listener judgments across the Coda voice pool. Here's how we did it: the framework, the methodology, the eval landscape, and the lineup we landed on.
Want to learn more about Rime and get expert guidance? Book a call with our team.
Four categories
We landed on four styles of voices: professional, formal, casual, energetic.
Customers were often asking for voices by those names, but not always. We’d hear things like "I want it to sound like an executive assistant but warm" or "friendly but this is still a bank." After talking to customers and reflecting, it was clear that the asks clustered into these four adjectives.
We started where the stakes were highest, but of course the universe is larger. While these styles are critical for large enterprises, where picking the wrong voice costs real money, we'll still need to add additional styles over time for use cases like narration, AI characters, regional localization, emotional customer simulation, etc.
Why categories, and not a linear continuum

The philosopher Ludwig Wittgenstein argued that words don't have fixed dictionary meanings. They get their meaning based on their use. What we call use cases, he called language games.
Ordering a burger at a drive thru is a language game. Rebooking a flight over the phone is a language game too. The same words (e.g. “hold”) spoken in one may have different meanings in another.
TTS voices are similar. Every voice has a different accent, timbre, prosody, phonation, etc., all of which affect whether it sounds right in a certain scenario. Voices carry semantic weight. Voices have meaning.
The right voice for a healthcare triage line is probably wrong for a fast food drive-through. And the right voice for a financial services callback is probably wrong for a hotel concierge. But not necessarily.
While a voice might sound professional, it could also sound formal. Or it could be formal and energetic. Forcing all the voices onto a number line with opposite adjectives felt too limiting. Voices are flexible.
In ML terms: the vector embeddings of voices live in a latent space where distance approximates perceptual similarity. "Professional" picks out a region in that space, not a single point. Two voices inside that region can be close neighbors and still differ on many other axes.
Now of course these are all just useful metaphors, not deterministic functions giving perfectly scientific voice descriptions (which would be impossible to build anyway). The map is not the territory.
Our style labels are concrete enough to be useful and ranked carefully enough to be trusted.
Professional vs. formal
This is the distinction customers ask about most.
Professional, for us, is the register of someone doing their job well. Confident, articulate, but human. A senior CSR who actually understands the policy. A nurse on a follow-up call. A claims adjuster who's been doing this for fifteen years and won't be flustered.
Formal is something else. Formal is occasion. It's the wedding officiant, the verdict being read, the airline gate agent reciting the boarding procedure. Formal carries ritual. It's the voice the moment demands. You'd use the professional voice for ninety percent of customer support. You'd use the formal voice for the legal disclosure at the end.
Both are correct. They're answers to different questions.
Casual vs. energetic
Casual and energetic look adjacent until you listen carefully. Casual is loose. Energetic is alive. A voice can be one without the other. Casual is the voice for an onboarding chat or a friendly check-in. Energetic is the voice for when something good just happened and the caller should hear you notice.
The labels also combine differently than you might expect. Professional and energetic coexist easily. A strong customer success voice is often both. Professional and casual sit further apart, closer to opposites though not strict antonyms.
How we ranked them
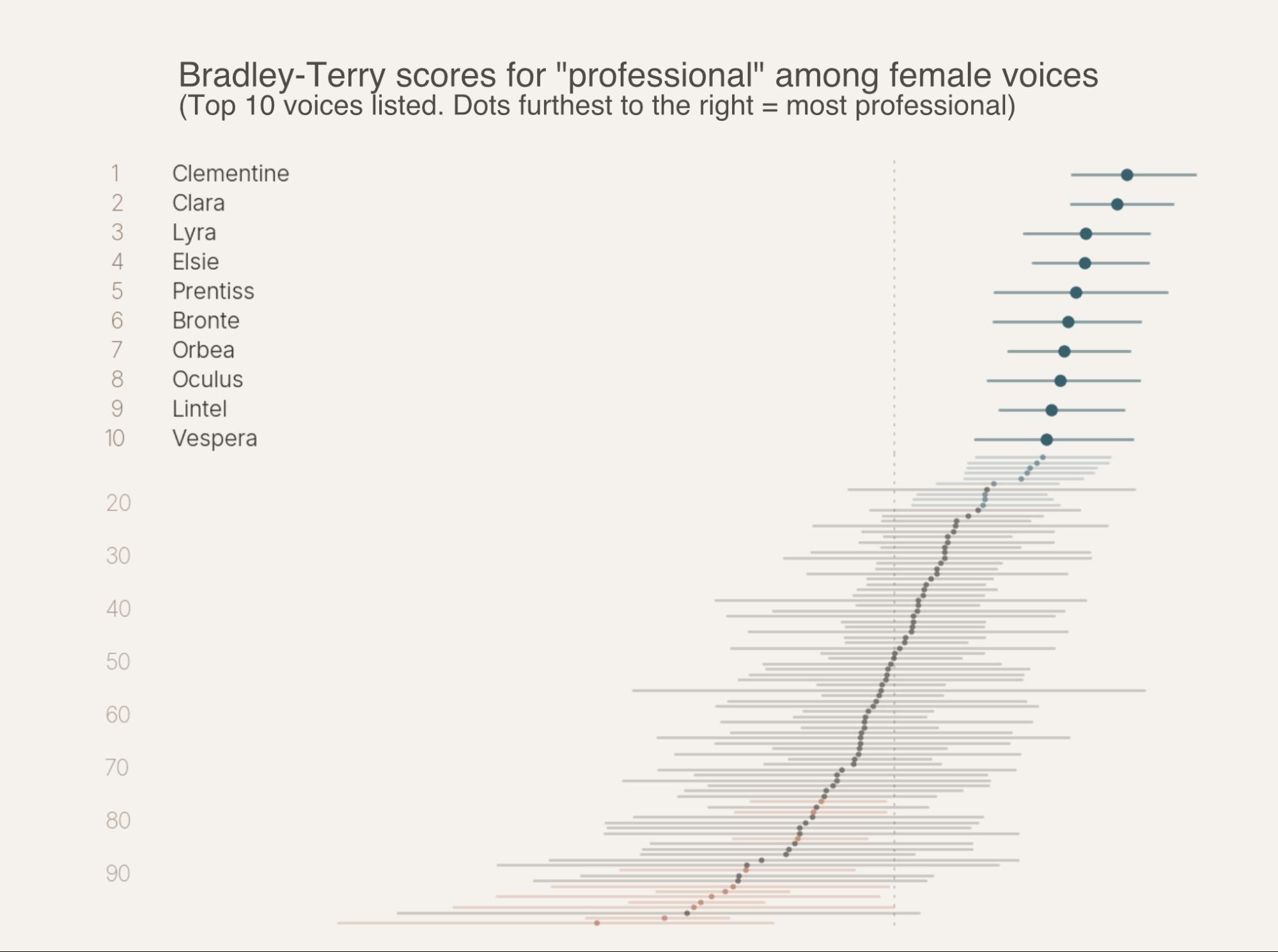
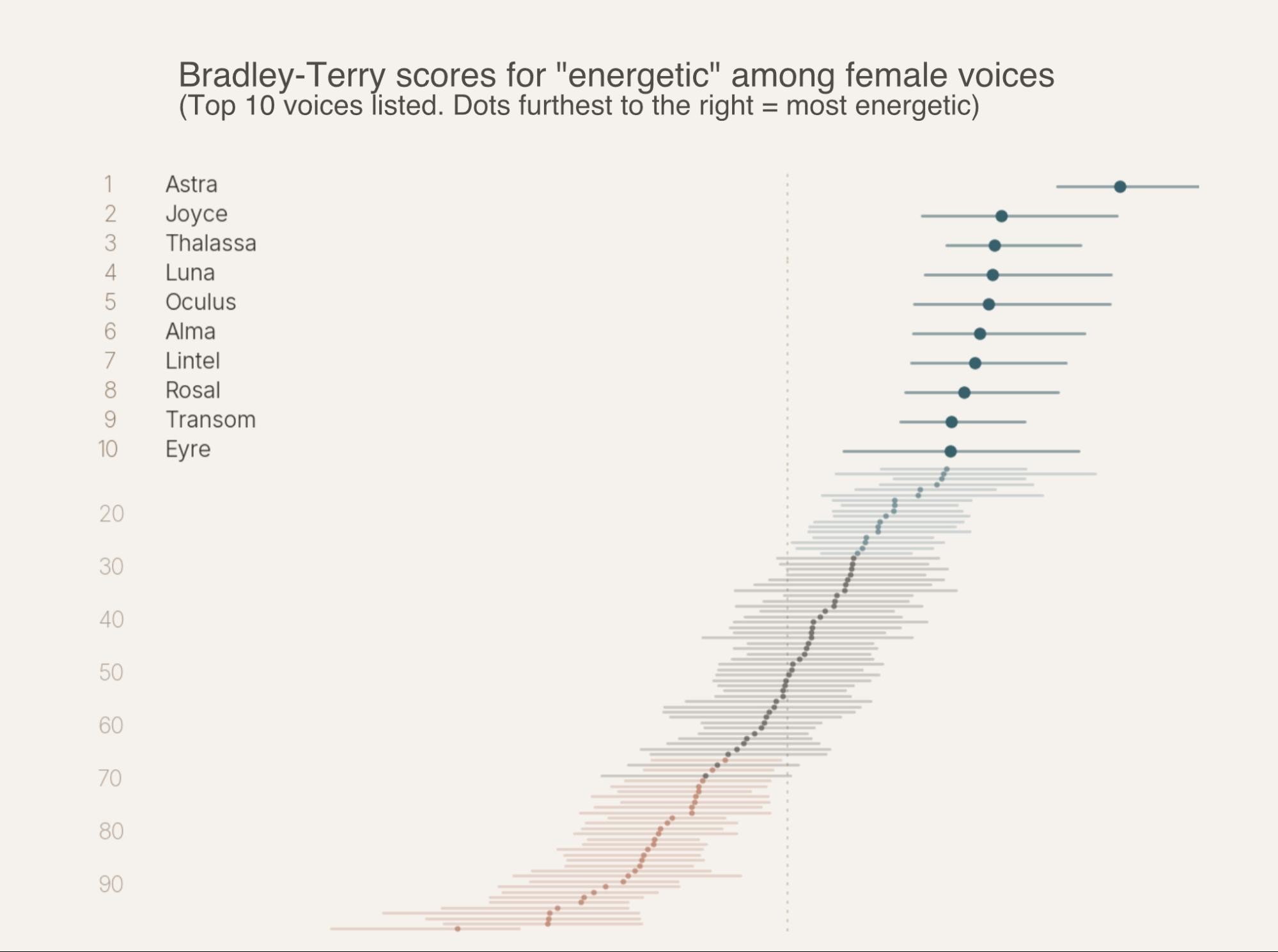
Once we had the four categories, we needed to order the candidate voices inside each one. Listening to a hundred voices by ear works for the top two or three picks. It falls apart at scale, and falls apart fast when you start asking whose ear.
Michael Cullan on our team built the evaluation pipeline. Here’s the shape of it:
Two to three clips per voice. A voice that sounds professional when reading one sentence can sound casual when reading another. We generated multiple clips per voice on prompts designed to probe each axis.
Pairwise comparisons, not ratings. We didn't ask listeners to rate voices on a 1-to-5 scale. We asked them to compare two voices on the same prompt and pick the more professional one, or more energetic, or whichever axis we were measuring. Pairwise judgments are noisier per trial but more reliable in aggregate. People are bad at calibrating absolute scores. They're good at picking a winner.
Bradley-Terry scoring. The standard tool for this kind of evaluation. Same intuition as Elo ratings in chess (pairwise wins produce a global ranking), but fit once over the full match set rather than updated trial-by-trial. That gives you proper 95% confidence intervals via bootstrap resampling. We ended up with roughly a thousand matches per axis per gender.
Stage gates. Two passes. A single-utterance "survey" round sorts the field with wide-but-usable confidence intervals, enough to separate strong from weak but fuzzy at the top. A multi-utterance follow-up on the short list tightens the rankings where the decisions matter.
Human listening on top. Once the math gave us a ranked list with confidence bands, Michael and the team listened through the top tier and pulled the final picks. The model points at where to look. Ears decide.
We ran this across all four axes, separated by perceived gender, and looked for voices that scored well in more than one place. Those are our default picks: voices that carry across registers without putting on a costume each time the prompt changes.
Why Podonos
We ran the evaluations on Podonos, an audio evaluation platform purpose-built for voice AI work. The pitch is simple: upload audio, write the comparison prompt, and within hours you have results from a vetted panel, not a Mechanical Turk fire hose.
Podonos handles everything that happens before a listener hears a clip: English fluency pre-screening, device and headphone checks, attention tests, environmental noise detection, intelligibility tests, audio-level normalization. Building that infrastructure in-house takes months and ongoing maintenance. Podonos already has it, and the noise floor is low enough that pairwise judgments reflect the voices, not the conditions.
Podonos also publishes independent research. They recently ran a benchmark of eleven leading TTS systems on US English. On the question that matters most ("Among the two audios, which one do you prefer in general?"), Rime ranked #1, beating ElevenLabs head-to-head 73% of the time and Cartesia 64% of the time across thousands of pairwise judgments.
On a separate question (which voice sounded most like a real human voice actor), we placed #6. We're fine with that. We don't want to sound like a voice actor. We want to sound like a real person you'd actually want to talk to. Not a voiceover artist. Not a YouTube influencer. Not an audiobook narrator. On the question of which voice listeners would rather talk to, we won.
Picking the right eval for the question
Podonos is one tool among several. The benchmark landscape has more options now, and they're not interchangeable. And they actually represent different language games in their own right too.
Rapidata is a platform we've used for several other evaluations. Their approach differs from Podonos in a few ways. Listeners are reached through mobile ads: short clips served on phones, anywhere, in any supported language. Reach is enormous, cost per judgment is low. The tradeoff: shorter clips, less control over the listening environment, a broader and less expert demographic. Great for wide-net multilingual reads, fast and cheap. Less suited to fine-grained register comparisons inside an expert pool.
Podonos sits on the other side of that tradeoff: listeners paid directly, screened heavily, evaluation structure highly flexible. Higher cost per judgment, lower volume, cleaner signal. That's what you want when you're picking between voices that all sound objectively good and the question is which one is more of a specific register.
Use Rapidata for wide-net multilingual reads. Use Podonos for fine-grained register work.
Public leaderboards (Artificial Analysis, LMArena, and similar) are incredibly useful for discoverability and quick scans. They're also a different game. How voices are presented, how questions are framed, and how providers optimize all distort the result. Model companies game these benchmarks, openly or otherwise. Our take to any developer picking from a leaderboard: do additional testing that reflects your actual environment, your use case, your specific language game. A benchmark rank is a starting point, not a verdict.
Production observability tools (Coval, Bluejay, Hamming) do something different again. They monitor voice agent performance in production: regression testing, reliability, failure detection, end-to-end pipeline observability. We use tools in this space for ongoing quality work. They aren't the right fit for "which voice sounds most professional?" But they are the right fit for "does this voice still perform when it's running through STT, an LLM, and a noisy phone line?"
None of these replaces the gold standard: evaluating in production during a pilot or POC, or siphoning off a slice of live traffic. The closer you get to a real customer in a real call with a real need, the more your evaluation tells you something useful.
It doesn’t matter if you win if you’re playing the wrong game…
To rank-order all the Coda voices on subjective stylistic axes with statistical rigor, Podonos was absolutely the right tool.
The voices we picked
Now finally, here are the voices we picked as winners in their category. Each one is live in the Coda catalog today (and usable in the Rime dashboard and API).
Professional
For calls where the customer needs to feel helped by a competent human: healthcare callbacks, financial services, insurance claims, enterprise customer support. The winners in this category are:
- Lyra (♀, 18–30): A warm young American voice; bright and lively.
- Clementine (♀, 18–30): A warm, lively twenty-something American voice; polished.
- Masonry (♂, 30–50): A confident, low Southern voice; authoritative without being loud.
- Lawton (♂, 60+): A warm American voice; calm and friendly throughout.
Listen to all the professional voices in Rime here.
Formal
For moments that carry ritual or institutional weight: legal disclosures, gate and platform announcements, official confirmations, regulated-industry communications. The winners in this category are:
- Lintel (♀, 18–30): A warm young American voice; both polished and lively.
- Eyre (♀, 30–50): A warm, friendly American voice; calm and easy to listen to.
- Bancroft (♂, 60+): A composed American voice; strong on both professional and formal registers.
- Marlu (♂, Australian, 30–50): An older Australian voice; low, mature, unhurried.
Listen to all the formal voices in Rime here.
Casual
For conversations that should feel low-stakes and human: consumer apps, onboarding, friendly check-ins, chat-style coaching. The winners in this category are:
- Hesse (♀, 18–30): A relaxed, easygoing voice.
- Luna (♀, 18–30): A bright, lively voice; energetic with a casual core.
- Beatty (♂, 18–30): An easygoing, distinctly casual American male voice.
- Godfrey (♂, 18–30): An easygoing, lively American male voice; casual at heart.
Listen to all the casual voices in Rime here.
Energetic
For moments that should land with momentum: QSR/drive-through ordering, callbacks delivering good news, consumer celebration moments, anywhere a flat read would feel like an apology. The winners in this category are:
- Astra (♀, 18–30): Bright, lively California; quick and expressive.
- Vespera (♀, 18–30): A friendly, lively young Californian voice; bright and adaptable.
- Parapet (♂, 30–50): A fast, lively Southern voice; energetic and grounded.
- Cupola (♂, 30–50): A confident, energetic American voice; professional with warmth.
Listen to all the energetic voices in Rime here.
One last note on Cupola. His description includes "professional with warmth". He landed in both energetic and professional and that's not a contradiction, it's the overlap we built the rankings to find: voices that are energetic and professional, casual and polished, formal and warm. The Casual and Energetic sample prompts above show the same idea, applied. Same scenario, two different language games. The voices we feel best about shipping are flexible, like real people.
Start building
If you're building a voice agent and you want a recommendation for which voice fits your use case, come talk to us. We’ll help you pick the right voice and get the best ROI.
Or just sign up and start building with $25 in free credits for Coda!
More from the lab
.png)
Guide: Design and run an A/B test of your AI voices on real calls using Claude and Cursor
Anything can sound great in a demo, but what do your callers actually prefer? Test multiple voices and vendors in your own experiment with this guide. Get benchmarks to measure against and prompts that you can execute in Claude and Cursor today.

