Which AI voice keeps people on the phone?

Most teams choose the voice for a phone agent by ear. Someone listens to a few options, picks the one that sounds right, and moves on. Miravoice, which builds AI interviewers for survey research, wanted to know whether that choice actually changes how people behave once they pick up. So they ran the largest controlled test of its kind, and presented it at the American Association for Public Opinion Research conference this year in Los Angeles.
A note on how the study came together: Rime commissioned and funded the research. Miravoice designed it, placed the calls, ran the statistics, drew the conclusions, and kept final editorial control. Rime had no hand in the data collection, the analysis, or the interpretation.
Lily Clifford, Rime's CEO, and Shreyas Tirumala, Miravoice's president, sat down to talk through the findings, and you can watch that full conversation on YouTube.
Below are the takeaways from the research, as presented by Miravoice.
What the study measured
Miravoice pulled about 36,000 landlines from a listed national sample and used them to place roughly 99,400 outbound calls between March 21 and April 8, 2026. The instrument was deliberately short and neutral: nine questions on local government and public transit, English only, with a median completion time of about two minutes and forty seconds. Every call opened with a disclosure, running twenty to thirty seconds, that made explicit the respondent was speaking with an AI agent. This was never a test of how convincingly a model can pass for human. It was a test of which voices people stay on the line with once they know exactly what they are talking to.
The design held the variables that usually muddy this kind of comparison. All voices called comparable samples in the same windows (weekday evenings and weekend afternoons, local time), with up to three attempts per number and no compensation offered to anyone. Twelve voices were tested in total, four from each of Rime, ElevenLabs, and Google, split evenly between male-coded and female-coded voices chosen from each platform's most popular or trending options. For the provider-level comparisons, Miravoice dropped each provider's weakest voice and compared the top three, so no brand is dragged down or propped up by a single outlier.
Three metrics anchored the analysis: how often people hung up during the intro (HUDI), how far people got once they stayed (cooperation rates and completion efficiency), and how often people asked to never be called again (do-not-call rate).

Hang-ups during the intro
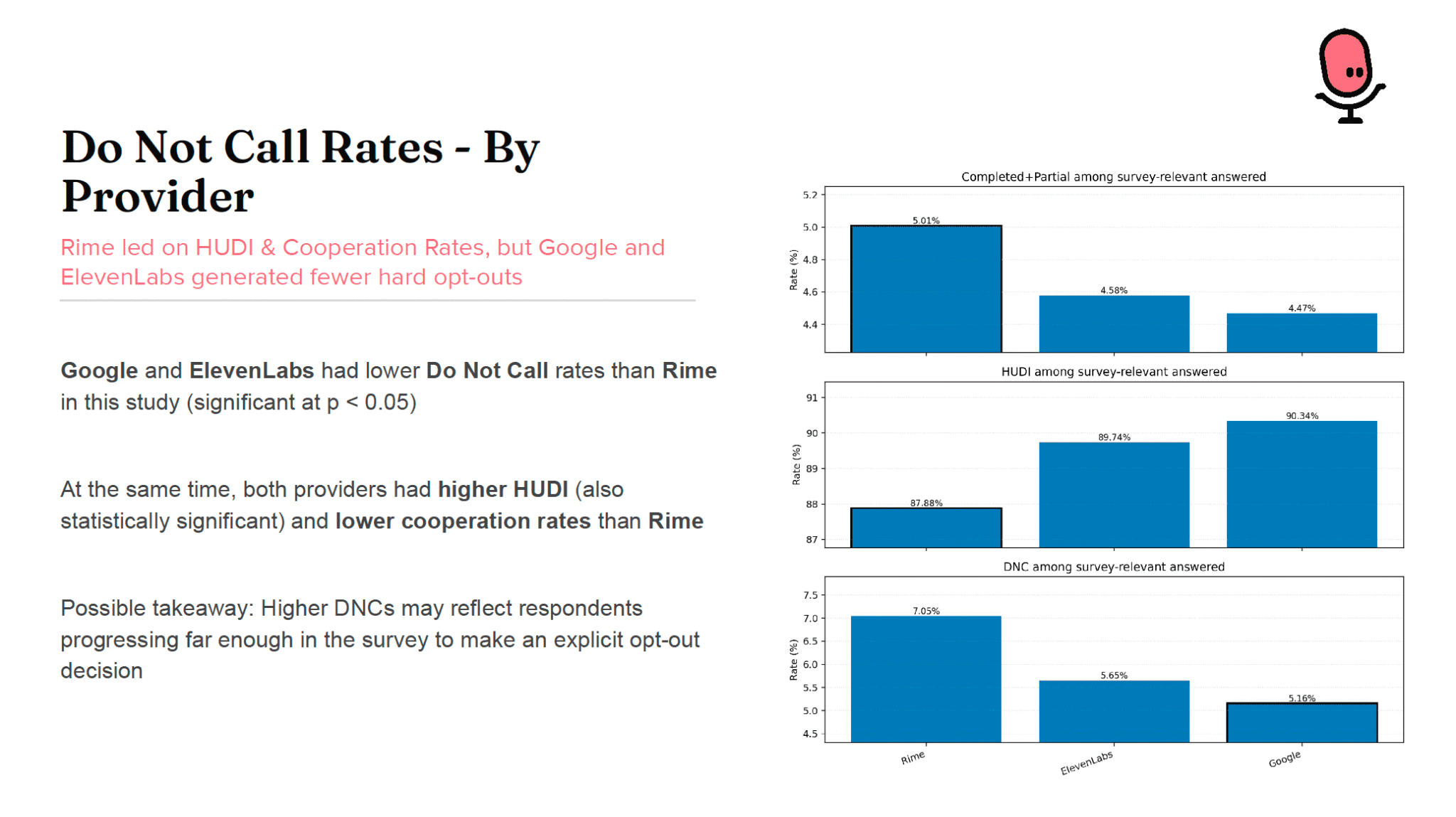
The first finding was about early break-offs. For a cold call to a landline that opens with a long AI disclosure, the overwhelming majority of people hang up no matter whose voice is on the other end, which is the nature of cold outbound. The question is what happens at the margin, and there Rime had the lowest intro hang-up rate of the three: 87.88 percent, against 89.74 percent for ElevenLabs and 90.34 percent for Google. The gaps were statistically significant against both competitors.
One detail is worth sitting with. The advantage did not show up in the first ten seconds, where no provider had a consistent edge. Miravoice's read is that the very first moments of a call are a reaction to the call itself, to caller ID and the fact of an unsolicited ring, rather than to the voice. The voice starts to matter only once someone has listened long enough to form an impression of it.

Staying on past the intro
The cleaner signal of the voice itself came from completion efficiency, which asks a narrower question: given that someone made it past a certain point in the call, how likely were they to finish? Rime had the highest observed cooperation rates overall, though those raw rates did not reach significance on their own. The survival-conditioned view is where the difference became clear. Past the twenty-five to thirty second mark, once the long intro was behind the respondent, Rime voices pulled away. At thirty seconds the advantage was statistically significant against both ElevenLabs and Google, and it held up after correcting for the fact that several post-intro metrics were tested at once.
There is a smaller result tucked alongside this one that points in the same direction. Among completed calls, Rime had the lowest median time to completion, two minutes and thirty-one seconds. Faster completion is easy to dismiss as a speed stat, but the more useful way to read it is as a clue about intelligibility. People who are not stopping to ask the system to repeat itself, or getting tripped up on an odd pronunciation, tend to move through a survey faster and finish it.
The do-not-call counterpoint
The most interesting result is the one that looks bad at first glance. Rime had a higher do-not-call rate than either competitor, 7.05 percent against 5.65 percent for ElevenLabs and 5.16 percent for Google, and the difference was statistically significant. Read on its own, that looks like people could not stand the Rime voices.
The trouble with that reading is that the same providers with the lower do-not-call rates also had the higher intro hang-up rates and the lower completion rates. It is hard to square "people couldn't wait to get off the phone" with "people took the time to formally opt out." The interpretation that fits the full picture is that a do-not-call is a downstream effect of engagement, not rejection. You do not bother asking to be taken off a list unless you stayed on long enough to make that decision. The people who genuinely do not want to talk simply hang up in the first few seconds, and never reach the point of opting out at all. This is exactly why a single headline metric will mislead you: look only at do-not-call rates and Rime looks worst, look at the full set and the opposite is true.
Gender coding barely registered
Going in, the intuition almost everyone shares is that female-coded voices outperform, a holdover from a decade of voice assistants defaulting female. The study found essentially nothing there. Female-coded voices had slightly lower intro hang-up rates and slightly higher cooperation rates, male-coded voices did slightly better on post-intro completion, and none of those differences was statistically significant. This lines up both with Rime's own data across millions of calls and with the older survey research on the gender of human interviewers, which also tends to find null effects.
The practical version of this is the part worth keeping. Voice-level variation was larger than any gender-level pattern, and the strong performers came from both groups. So when the instinct is to ask for "your female voices," the better question is which specific voice performs in your specific use case.
What it means for anyone deploying voice
The throughline took a hundred thousand calls to earn, but it is simple. The voice is a design parameter that moves real metrics, not an implementation detail you set once and forget. A few things follow from that.
Test more than one voice on your own production traffic, because the variation Miravoice saw between individual voices was large, and what works for a public opinion survey will not automatically work for support or sales. Do not let a single number make the call, since the do-not-call result shows how one metric in isolation can point you in exactly the wrong direction. And when people refuse or opt out, read the refusal in context before acting on it, because sometimes it means the voice is wrong and sometimes it means people were engaged enough to bother.
This is one early, exploratory look, with the usual caveats about a single study on a single survey topic. Miravoice is already pointing at the next questions: a closer analysis of pitch and frequency rather than gender coding, more providers, and how cadence and speed affect all of these numbers. We funded the study, we did not get to grade it, and it is more useful for that.
You can watch Lily and Shreyas walk through the findings in full here. For the complete deck or questions on methodology, Shreyas can be reached at shreyas@miravoice.com.
To learn more about Rime’s Voice AI models Coda or Mist, you can sign up for free to start listening to voices today.