Launching Arcana v3: Authentic TTS built for scale

At Rime, our mission is to make voice the default interface for technology.
Voice is the most natural way to communicate. It’s faster than typing, more expressive than text, and critical for multimodal experiences. But for voice to become truly ubiquitous, enterprises and developers need models that are realistic, fast, and reliable in production.
So far Rime voices have powered over one billion calls. After growing 5x in the past 3 months, we’ve learned that the best speech model must combine both ultra high-quality voices and a set of primitives to ship at scale.
Until now, Arcana v2 was the most realistic and expressive TTS, but it was missing key capabilities. It needed to be faster without sacrificing quality. And it needed to integrate with enterprise-grade infrastructure powering high-volume, real-time voice AI applications at scale. So over the past several months we’ve been hard at work, cooking up something new.
Today, we’re excited to announce our new flagship model, Arcana v3!
Finally authentic TTS built for scale!
Overview
So what does it take to make voice the default interface in enterprise applications?
- Authentic, natural-sounding voices
- Fast enough for real-time interactions
- Reliable under sustained, high-volume load
- Deployable wherever enterprises operate
What's new?
- Model latency down to 120ms TTFB
- Multilingual codeswitching across 10+ languages
- Word-level timestamps
- Increased concurrency of 100+ generations per machine
- Improved developer ergonomics for on-prem
How does it sound?
<div data-src="https://pub-6ab2c5a795554615a09514e6a406f945.r2.dev/arcana-v3-blog/clip-1.mp3" data-caption="Multilingual code switching: Hi, thanks for calling customer support. I can help you in multiple languages. Auf deutsch helfe ich Ihnen gern weiter. En français, je peux vous assister immédiatement. 日本語でもサポートできます。"></div>
<div data-src="https://pub-6ab2c5a795554615a09514e6a406f945.r2.dev/arcana-v3-blog/clip-2.mp3" data-caption="Multilingual code switching: Hey there, I'm Anna, and I'm here to help. Olá, eu sou a Anna e estou aqui para ajudar. Hola, soy Ana y estoy aquí para ayudarte."></div>
<div data-src="https://pub-6ab2c5a795554615a09514e6a406f945.r2.dev/arcana-v3-blog/clip-3.mp3" data-caption="Emotional range: Oh gosh, I'm so sorry to hear that. Oh gosh, I'm so happy to hear that!"></div>
<div data-src="https://pub-6ab2c5a795554615a09514e6a406f945.r2.dev/arcana-v3-blog/clip-4.mp3" data-caption="Multilingual filler words: Eh no lo sé con eh con exactitud."></div>
“At Trillet, we’ve exhaustively tested every major TTS model. Rime’s Arcana v3 is both the fastest model on the market and delivers the most compelling voices we’ve heard. We’ve seen callers stay on the phone longer and conversations end with higher engagement when using v3.”
— Ming Xu, Co-Founder & COO, Trillet (AI call answering platform for small businesses)
And how does Arcana v3 stack up against the competition?
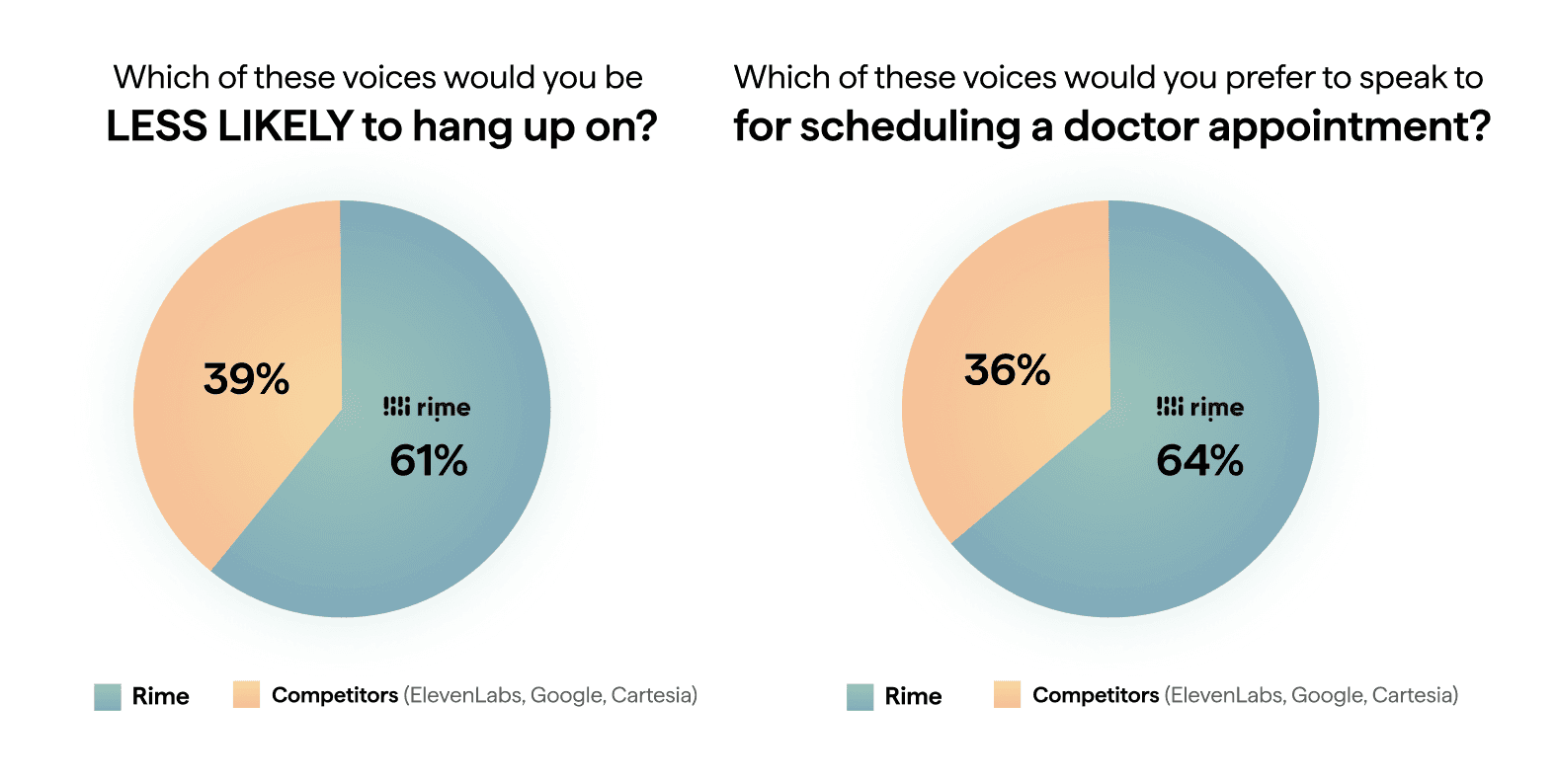
In collaboration with Rapidata, we ran a large-scale qualitative analysis on listeners within the United States to determine how Rime stacks up against our competition on outcomes our customers care about - not just isolated examples within an Arena. On the question, "Which of these voices are you LESS LIKELY to hang up on?", Rime wins against ElevenLabs Turbo v2.5, Google Chirp, and Cartesia Sonic 61% of the time. On the question, "Which of these voices would you prefer to speak to for scheduling a doctor's appointment?", Rime wins 64% of the time.
“Rime's Arcana v3 represents a significant leap forward in real-time bilingual text-to-speech technology. Our independent evaluation reveals that Arcana v3 outperforms ElevenLabs Turbo v2.5 on speed, quality, and bilingual capabilities - making it the ideal choice for voice AI applications serving diverse, multilingual user bases.”
— Sumanyu Sharma, Founder & CEO at Hamming (Voice agent evals and QA platform)
"When presenting to our enterprise partners, four out of every five people we showed it to preferred the Rime Arcana v3 multilingual voices to the ElevenLabs Flash 2.5 model."
— Jay Patel, Co-Founder & CTO at AviaryAI (AI voice agents for financial services)
Deep dive on Arcana v3
Latency
Latency is the key difference between voice agents and IVR/IVA contact center automation applications that are so natural they put you at ease and those that are so frustrating that you mash the 0 button to talk to a human operator.
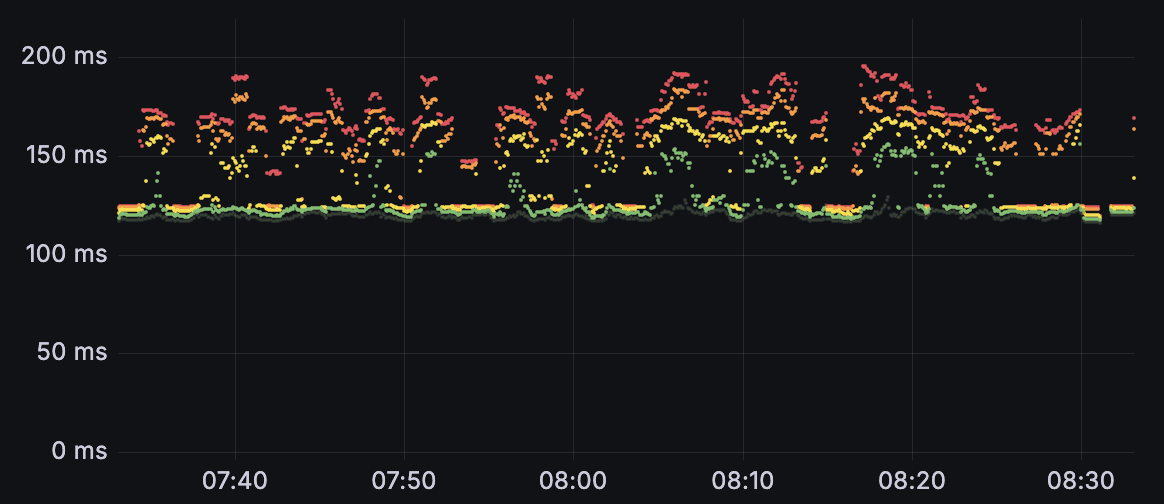
For human-level performance, conversational turns should be under 700ms. Arcana v3 delivers 120ms on-prem model latency and ~200ms TTFB via cloud API, enabling truly real-time conversational experiences, whether it’s for an IVR system or an AI voice agent.
This means you can now build real-time voice apps with barge-in or mid-utterance control using Arcana.
Internally, we track latency obsessively.
Rime’s Arcana v3 delivers exceptional voice quality with the efficiency and speed required for production-scale deployment. Running Arcana V3 on Telynx's global infrastructure allows our customers to build high-performance AI agents faster and more cost-effectively than ever.
— David Casem, CEO at Telnyx (Full-stack conversational AI and telephony platform)
This performance gain is the outcome of a series of model architecture changes, inference optimizations, and a vertically integrated serving stack designed specifically for TTS. Behind the scenes there are two models powering Arcana v3: a lightning fast English-Spanish bilingual model; and a slightly less snappy but still very fast multilingual model supporting every language.
Multilingual Support
Arcana v3's TTS AI supports 10 languages out of the box, with more coming soon. And each of our voices can speak every language. This allows for conversational AI applications where the voice AI agent can switch to any of our supported languages in the middle of the conversation, without sounding like a different speaker.
Today we support the following languages:
- English
- Hindi
- Spanish
- Arabic
- French
- Portuguese
- German
- Japanese
- Hebrew
- Tamil
But multilingual support isn’t just about coverage, it’s about quality. In internal and partner evaluations, Arcana v3 consistently delivers natural prosody, correct pronunciation, and stable voice identity across languages.
“Most TTS models are tuned for English, but voice AI applications are used by people around the world. The new Arcana v3 model generates high-quality speech across 11 languages in real time. This allows you to build voice agents that feel fast and natural to converse with no matter where your users may be.”
— Tom Shapland, Product, LiveKit (Open source voice AI developer platform)
You can see this in action in this language-switching demo (+16287269080) built with Rime on top of LiveKit, where agents seamlessly switch languages mid-conversation in real time.

So whether you’re deploying globally or building multilingual experiences at home, Arcana v3 is designed to sound native.
Word-level Timestamps
Modern voice apps need more than just audio, they need structure and control. To that end, Arcana v3 brings word-level timestamps to Arcana, enabling:
- Precise text-audio alignment
- Real-time highlighting and captions
- Better interruption handling
- Smarter agent orchestration
These timestamps are available alongside JSON-based WebSocket streaming, fully supported by LiveKit and Pipecat by Daily, making it easy to integrate Arcana v3 into real-time voice pipelines.
Enterprise-Grade Developer Ergonomics
Arcana v3 significantly improves the on-prem experience:
- ORCA headers for automatic scaling
- No manual tuning or fragile configs
- A single machine can support 100+ concurrent generations
- A full suite of TTS-optimized metrics for observability
These metrics are purpose-built for voice applications, not generic ops dashboards, so teams can understand latency, concurrency, and throughput at a glance.
On the cloud side, we rebuilt our inference stack from first principles. We now serve Arcana v3 on our own bare-metal infrastructure, written in Rust, with geo-optimized endpoints across North America:
Hit whichever endpoint you want, we’ll take care of the rest. This architecture gives us tighter latency bounds, better reliability, and more predictable performance at scale, plus internal alignment with our customers’ on-prem deployments.
Rime’s Arcana v3 voices are also integrated into Together AI. By running Rime's Arcana v3 TTS colocated alongside your LLM and STT models you can bring latency down across the stack.
Rime's Arcana v3 models deliver voice quality that sounds natural in production—native code-switching, low latency, the kind of TTS that keeps users in the flow. We're excited to bring them to Together AI so teams can run this alongside their LLMs and speech models on unified infrastructure.
— Rishabh Bhargava, Director of ML, Together AI (AI native cloud infrastructure platform)
Start building now!
To start using Arcana v3, just call the Rime API with the same arcana model ID and you’ll automatically get audio from the new model.
"text": "Um hi! This is Vespera speaking.",
"speaker": "vespera",
"modelId": "arcana",
We’ve also improved our documentation and added some new Quickstart guides (including a voice agent tutorial with Rime+LiveKit) to help you build.
You combined the speed of Mist v2 to Arcana and the richer tone of Arcana into one delightful model. I’m really looking forward to deploying it on premise for our demanding needs!
— Bob Summers, Founder & CEO at Goodcall (Agentic voice AI platform to automate customer service)
What’s next?
Even with all the recent progress and hype, we believe we’re still at day 0 for voice AI adoption. And at Rime we’re always still just getting started.
In the coming months, we’re planning to empower voice AI builders with even more enterprise-grade capabilities:
- Enhanced naturalness and emotional range
- Additional languages, accents, and dialects
- Global deployments across South Asia, Europe, and other regions
- Streamlined on-prem implementations
- Custom pronunciation in Arcana with phoneme-level conditioning that will bring Arcana in line with our Mist-family models
- Even higher concurrency models, further driving down total cost of ownership
- Additional partnerships with cloud and edge network providers
All of these improvements are in the service of making voice AI truly ubiquitous. We can’t wait to see what you build!